Managing Parallel, Part 2: To thread or not to thread
Managing Parallel, Part 2
This post is all about the types of parallelism avaiable in general on a modern machine. There are many. It’ll focus on open operating systems like Linux, and at times we’ll talk about others like OS X or earlier operating systems where applicable. Instead of talking about the hardware and software separately, we’ll go back and forth when needed. First we’ll start off with an overview on the types of parallelism that we could have. Lets start off with some terminology and a really high level overview before diving in.
Software Managed Parallelism
In general there are three levels of parallelism managed by the operating system, and also three that are generally exploited by the hardware. Starting with the software managed (and by managed, I mean scheduled, or “when and where to run”) we have the process (green at the bottom, figure below) as the most heavy weight. For a long time, everything was a process. There were no threads to be had. Before widespread OS threading support was available (or needed), user-space threading was (and still often is) used to context swap between multiple units of work. In modern systems, the next smallest unit of parallelism is the kernel managed thread. Each process has what is generally called a “main” thread which it uses upon start-up and is initially scheduled by the operating system (for systems that use software managed threads, there are also ones which have hardware scheduling which we’ll cover in a bit). In general the order from largest most monolithic to smallest and finest grain is: Process, Kernel Thread, User-space Thread.
Each process can have many OS managed threads. OS managed threads in turn, including the main thread, can have many user-space managed threads. User-space threads are managed, not by the operating system, but typically by a run-time or manual (user defined) scheduling system (again, details will be discussed in later in this post). Processes, threads, and user space threads can also leverage parallelism mediated by the hardware such as SIMD, out-of-order execution and pipeline parallelism. This is of course, is outside of the control of the software that runs on the hardware, however it is there none-the-less.
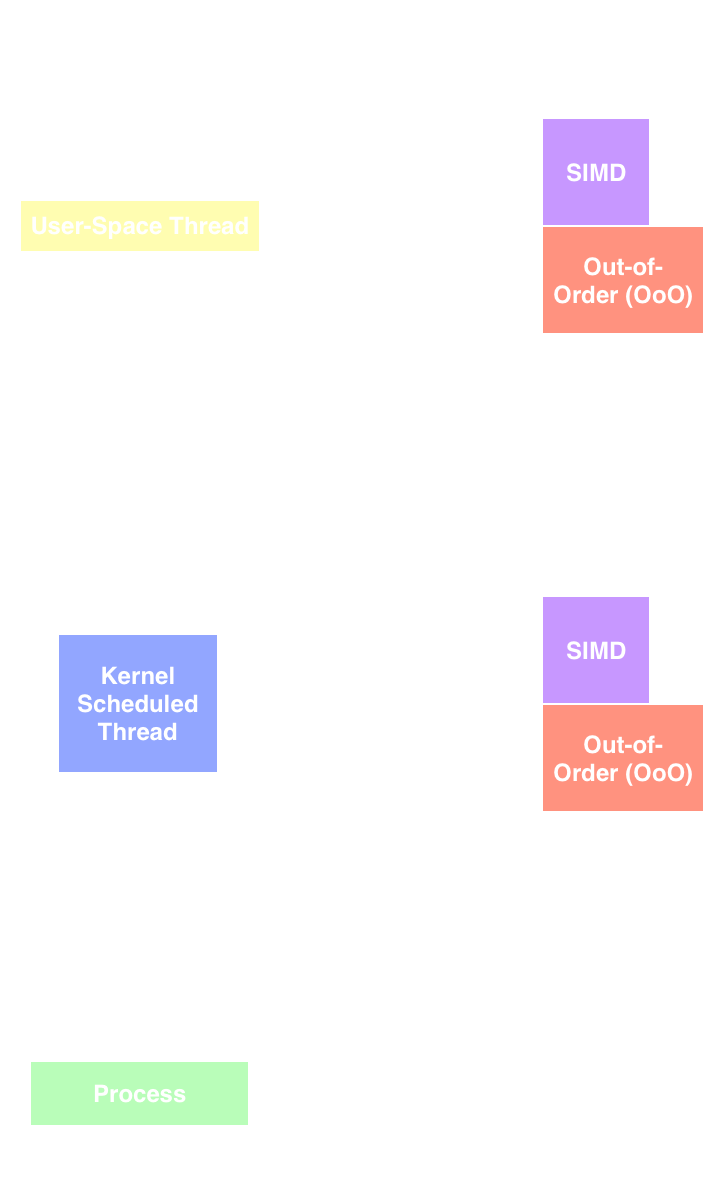
Hardware Managed Parallelism
Unlike software, hardware is capable of being completely parallel. On every clock tick, signals can be processed. This can be as wide as timing constraints allow (a topic for another post). I want to go over the three main sources of parallelism in modern processors: SIMD, pipeline, and out-of-order execution. Let’s start with SIMD, which stands for single instruction, multiple data. It is one of the most naive forms of parallelism available to hardware but also one of the most effective for many workloads. Using the previous posts assembly line termimology, SIMD is like adding N workers of the same time at one point in the assembly. Looking at it in abstract:
SIMD parallelism ostensibly provides (at least the illusion of) a compute element that can operate on multiple elements of fixed width at the exact same time. I say illusion because even though the instruction set architecture specifies a vector of N width, you could end up doing sequential operations or smaller vector ops on that width of data. At a high level it looks something like the below picture.
The processor has instructions that specify a vector operation, in this case, an add instruction. The processor also has registers that are theoretically architected to match the width of the actual vector unit. I say theoretically because these can be virtualized, however, even the virtualized widths should have the illusion that the registers have the same width as the vector instruction. I must emphasize that there is no guarantee that this will be the case (unless guaranteed by the ISA). The register only has to be wide enough to feed the actual physical vector unit. Given N cycles the vector processor takes and performs the operation on the two registers. The result could be written back to a third register, but in our example it will write back to register A. The goal of a vector op is to perform multiple ops with hopefully a wide load from memory to the registers. The load from memory is interesting, and I want to take a second to talk about that specifically since it is the dominant factor, not the compute in many cases.
Most cache lines are 64-bytes in length. In total that means that each cache line has 512-bits. Some cache lines are larger, e.g., 128-bytes, regardless of exact size, the concept of minimum granularity is what counts. No matter how little you the programmer asks for, you will always get that minimum granularity. DDR (your main memory, RAM) is accessed in bursts. For every cache line that is filled, your core accesses DRAM multiple times which is a burst length (where N=8 for most systems), so for one cache line 8 DRAM accesses. Every time the processor goes to DRAM takes energy, I’ll leave energy to a future blog post in this series. Okay, back to memory and SIMD vectors. Making vectors wider than the unit of coherence can strain the memory system so it becomes critical to get as much cache line re-use as possible so that a full burst isn’t needed for every vector operation, otherwise much of the performance netted from the SIMD unit could be lost due to memory latency. Naively implementing everything as SIMD is quite foolish without profiling and hardware tuning as your performance will likely suffer.
Another classic form of hardware parallelism is a pipeline. I’m going to explain how and why it works for hardware in two different ways, then go for the software corollary. First, lets get back to the original worker and assembly line allusion from part 1. If we have an assembly line and there is a task to perform, the rate that items come off that assembly line are limited by the speed that each worker can perform their tasks. Let’s assume that worker A has a task that has three main steps that each take a single unit of time, so total time for completion of a job for worker A takes three units of time. Now lets assume that we can divide that job into three pieces, and get two new workers that can each perform part of the main job. So now each worker takes a single unit of time to perform their job. In this new “pipelined” arrangement every single unit of time one job is completed. This is in contrast to the single worker doing the job with three tasks where only one item was completed for every three units of time. This is HUGE, we’ve now parallelized something temporally (in time), something that wasn’t immediately obvious how to parallelize. Now take the picture below:
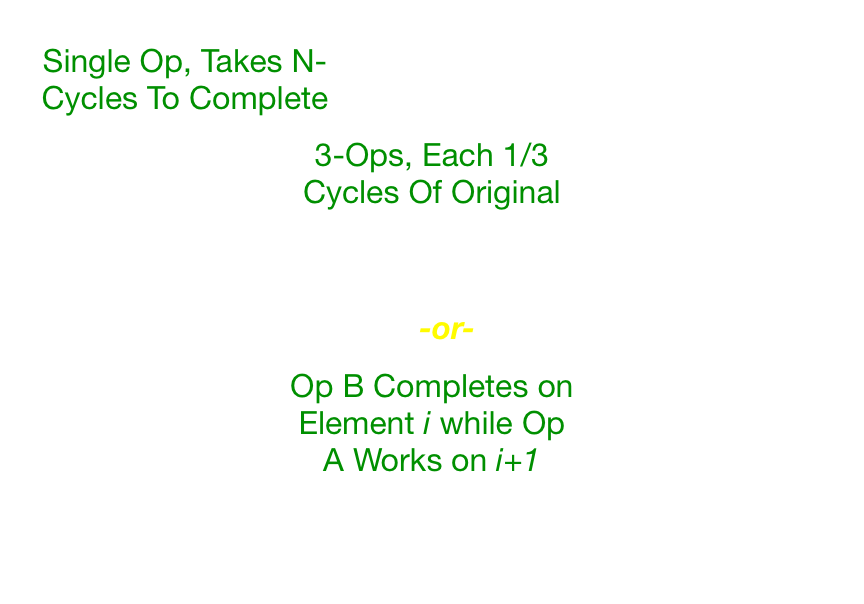
A single instruction has the property that to complete it there are three discernible sub-tasks or stages. Each sub-task now takes of the time compared to the single monolithic operation. So what’s the downside? Well, there is very little, unless the cost of communicating a job from one worker to the next is high. If you have single instruction, and no follow-on then there is really no benefit to pipeline decomposition of the operation. You’ll still have the 3-unit of time latency (using our previous example) as the non-pipelined instruction. The advantage is that if you have lots of instructions then you’ll get one operation every unit of time, whereas before the core was limited by the slowest single step (the one we broke up). Another fortuitous side-effect in hardware is that each shorter task in hardware is now simpler and requires less logic. For hardware this typically means that you can run it at a higher clock rate. In general more pipeline stages, and less actual work for each stage means higher clock rates and more throughput (until you run into the limits of your latch and clock skew). Where this largely falls apart is branching (perhaps a subject for another blog post, in the interim see: Pentium 4 Pipeline Problems).
In addition to pipeline parallelism and SIMD parallelism, the way almost all high performance cores get performance is through out-of-order execution. Out-of-order relies on independence of instructions within the instruction window. Looking at the example below:

we have a simple ROB with instruction A at the head and D at the tail. The only dependent instruction within the ROB is C which is dependent on the result of A. All the other instructions can be issued in parallel except for instruction C which must wait for instruction A to complete. These instructions are committed (seen as complete by the memory system and effectively by the program) in order from the head of the ROB to the tail. This parallelism is limited by the amount of independence in the instruction window, the size of the instruction window, and the number of functional units to issue instructions to in the core.
The performance of hardware parallelism is often limited by the memory fabric feeding the functional compute units. We’ll look at those issues in a future post.
So we’ve talked about many means of extracting parallelism, but what about parallelism the programmer can control (most of the hardware mechanisms are largely outside of what you can influence, however there are exceptions where instruction scheduling can have a huge difference). In the next post we’ll deep dive into software managed parallelism.