A short intro to stream processing
What is stream processing and how does it relate to data-flow?
It seems that data-flow / stream processing is becoming quite popular, as of late. But what is it exactly, and can we define what is generally called “stream processing” today with actual data-flow programming. How about “reactive programming”? Is there a difference? Not at all, they’re each special cases of the other. Before talking about the differences, let’s talk about what the streaming paradigm is, where it came from, and then differentiate between the current programming modalities.
The concept behind stream processing is a very simple one. By connecting sequential (syntactically) compute kernels via streams so that each compute kernel can compute independently, a model to construct parallel applications emerges.
|
It naturally arises from the job shop (or assembly line model) common to modern factories throughout the world. Each compute kernel in a streaming application is like an independent worker, performing a relatively sequential task (perhaps however with instruction level parallelism) on a finite (but unknown quantity) of streaming data The first data flow language is believed to be credited to Jack Dennis. Since, there have been dozens of streaming languages, frameworks, and even hardware (I’ll revisit these in a future post, many are pretty cool). Some examples of streaming languages and libraries include RaftLib (my own), ScalaPipe, StreamIt, S-Net, and others (there’s a long list link).
Streaming systems explicitly enable pipelined and task parallelism; tasks can execute as soon as the required resources are available. On distributed, heterogeneous hardware (almost all hardware is heterogeneous these days, e.g., ARM’s big.LITTLE, AMD’s APU, Intel Iris graphics + i7, etc.). These systems are hard to program, often requiring a mix of PThreads, OpenMP, OpenCL, and many system calls to get them to work together. Often much of the coding work to be done is nothing more than detail oriented boiler-plate. The details really determine the performance (more on this later). With non-expert programmers in mind, intuitive linguistic semantics are quite important to parallel systems. As discussed in a previous post, the boilerplate is anything but intuitive. It is hoped that data-flow / stream processing can address this issue. Linguistically, stream processing systems can take many forms. Traditionally programmers assemble building blocks of “kernel” compute units. These kernels can be called filters, threads, kernels, bolts, etc. The name doesn’t really matter, just know that these are the compute units.
I mentioned before that kernels are sequentially constructed units. This is huge, since programmers can author sequentially and extract parallel computation through other means (compiler/run-time/hardware). Things like memory models and other non-deterministic behavior (classic race condition type behavior) don’t have to worry programmers using a streaming or data-flow style to construct parallel applications. These complexities are abstracted away through the run-time and language itself. Another benefit is the reduction of spaghetti code. Strict stream processing semantics dictate that all state is packaged within a kernel. This cannot be enforced easily within libraries, without modifying the compiler, which is one advantage of full language solutions (although backwards compatibility with classic languages such as C++ usually trump this advantage). To summarize, stream processing has two immediate advantages: 1) it enables a programmer to think sequentially about individual pieces of a program while composing a larger program that can be executed in parallel, 2) a streaming run-time can reason about each kernel individually while potentially optimizing globally.

|
The streams that connect each “kernel” are usually interfaced with as a first-in, first-out (FIFO) queue. The exact allocation and construction of each queue is dependent upon the link type (and largely transparent to the user for most streaming systems). The FIFO itself abstracts away the parallel behavior from the programmer, leaving her to reason about a “snapshot” of time when the kernel is active (scheduled). This FIFO makes things like fault tolerance and parallelization easier to implement. Largely this results from the reduced variable space that run-time developers must contend with when implementing parallelization frameworks or fault-tolerant solutions. The FIFO between two independent kernels (see example above) exhibits classic queueing behavior. With purely streaming systems, these can be modeled using queueing or network flow models.
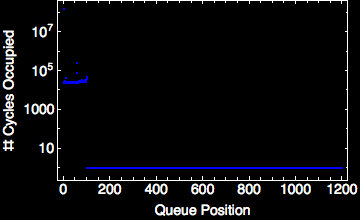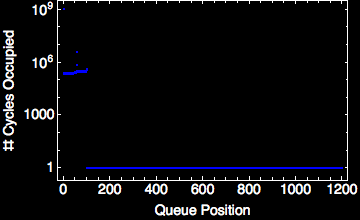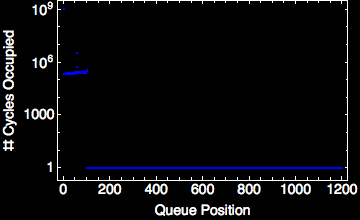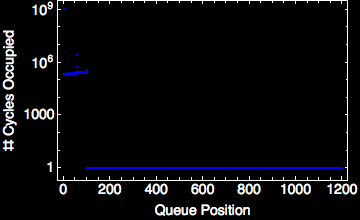
|
In addition to simpler logic, stream processing enables easier heterogeneous and distributed computation. A compute kernel could have individual implementations that target an FPGA and a multi-core running within the same application, known as “heterogeneous computation” or “hybrid computing”. Even when implementations for each resource aren’t available, classic techniques such as dynamic binary translation (DBT) could be employed (in the past DBT has had issues since the area to translate first had to be defined, with streaming it is implicitly defined). As long as the inputs and outputs are matching, the application will run correctly regardless of which resource a kernel is scheduled to execute on. Brook, Auto-Pipe, and GPU-Chariot are examples of heterogeneous streaming systems. Stream processing also naturally lends itself to distributed (network) processing, where network links simply become part of the stream (optimally this will is transparent to the programmer as well).
###Other types of streaming There are other systems that have less classical streaming styles. On many levels, Google Cloud Dataflow can be considered a streaming system. Storm, Samza, and Spark are open-source streaming platforms that are focused on message-based data processing. These systems differ from other classic “streaming” modalities in that they eschew point to point communication for centralized brokers to distribute data. A central broker makes providing fault tolerance simpler, however it also stifles many opportunities for optimization available to traditional streaming systems (queueing network optimization, some scheduling optimizations, etc.). Blocking and decentralized control of classic streaming systems enable tighter optimization with much lower overhead than most of the current centralized systems. It is, however, much easier to manage a centralized system within a data center. So what you get in terms of centralized management you loose in overall system performance. Which is one reason you see these types of systems taking off for “big-data” applications (although through addition of efficient fault-tolerance I hope to see some other systems take off).
###Reactive programming Reactive programming is actually a special case of data-flow/stream processing. At a high level reactive programming can be thought of as a spreadsheet (see figure below).
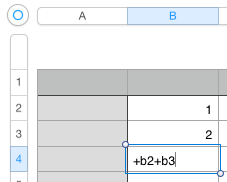
|

|
Obviously we’ve just reduced the latency by decreasing the queue length. This is where the “reactive” part comes in. As we’ve mentioned before, all streaming/data-flow systems execute kernels only when data is available (the kernel itself decides if there is enough of each port’s data). In the reactive case (using the example above), the values in B2 and B3 are persistent within the kernel itself (it saves state) so that the sum operation can be completed by combining data from each port (both new and stored data). By reducing the queue to a single entry so that the input stream is “immediately” visible to the worker kernels we can implement reactive programming from a general data-flow/streaming model. One key take-away from this is that while data-flow/streaming systems typically trade off latency for throughput, this special case makes the opposite decision by ensuring latency is extremely small compared to human perception.
###Conclusions Stream processing, data-flow programming, and reactive programming are all differing names for the exact same paradigm. The paradigm is a model of parallel computation that favors compartmentalization of state and sequential execution within actors to facilitate a simpler programming model for parallel programming. Each sequential actor is “stitched” together with streams. A stream could be a data-base, a shared memory FIFO, or even a single element buffer (in the case of the reactive variants). Stream processing has had its share of naysayers in the past, and there still are quite a few. This isn’t for lack of reason either, the classic split/join modality that is predominant today has held up relatively well. It is also fair to say that stream processing proponents tend to roll it out whenever people have issues with the current paradigm without much follow through in terms of actual run-time/language support.
What is different today is the amount of parallel hardware in everyones hands. Even phones have multiple cores, and heterogeneous accelerators (GPUs, etc.). Programming these devices is a nightmare with most of the current modalities. Combining bits of OpenCL, C, and Java to create a coherent system is quite time consuming. Stream processing provides a solution. The state/logic compartmentalization makes it much easier for a compiler (and scheduler) to figure out where to run which pieces of an application where. The second reason I think it is here to stay is that it breaks the “split/join” death grip on parallel execution. By enabling pipelined and task parallelism, the run-time can do many more concurrent actions than are possible with the split/join model. This parallelism is critical to taking advantage of the hardware available. On the same vain as enabling pipeline parallelism, streaming also enables authors to build parallel applications without having to worry about locks, race conditions, etc. that make parallel programming hard in the first place. Lastly, many of the applications that could take advantage of vectorization (increasing ILP) don’t. This is partially do to how conservative compilers must be when deciding when to emit vector instructions. With stream processing, it can easily be determined that the input data is aligned and that operations on streams can be vectorized (both statically and during run-time).
So which streaming run-time will be the best? Who knows. Personally I’m just happy to see my dissertation topic start to take off. In 2010 I felt like this guy:

These days I can’t go to a CS/CoE conference without sitting through at least one (often more) presentations on stream processing/data-flow programming. I suspect eventually we’ll see some standards emerge, however in the interim the competition to attract users is fierce and that is good. Hopefully a few systems will emerge that can withstand real-world users so that the framework exists for a standard to be formed. In my next post I’ll take a look at some of the models used for streaming systems, and after that I’ll discuss some of the data-flow hardware I mentioned at the start of this post.