Managing Parallel, Part 1: Queueing, Work, Oh My!
Managing Parallel, Part 1
Parallel execution is a great thing. It enables the employ of multiple workers to get a job done faster. If all the workers perform exactly the same function, then the problem can be divided up evenly amongst the workers. This is the simplest form of parallelism. Picture a room full of typists.

Each one can type. It doesn’t matter that each is typing something slightly different, they’re all doing part of the larger job (typing all the letters that need typed). There are a few things to consider with this model:
- Typing speed, sure they all do the same job..but maybe one typist had a lot of coffee or perhaps has a slightly more oiled machine. They’ll go faster than the others.
- What happens if one typist gets a letter with a single sentence, but others get long letters? If uniformly distributed this wouldn’t do too much to our overall throughput, but what happens if we’re unlucky and that one typist gets a batch of only short letters? The short letter typist would likely finish early and go home unless we can do a better job of load balancing. Non-homogeneous jobs are common, and must be dealt with.
- The stacks of papers next to each typists machine take time to move, and coordination to allocate. Communication takes time and energy.
The most optimal model is a combination of multiple similar workers (like the typists), but arranged with workers that perform other functions. Henry Ford demonstrated an assembly line approach that gave each worker basically one job.

He put these workers in a line where the cars were passed from one worker to the next as they were built up. This assembly-line or job-shop model is what we want to achieve with our parallel programs. It’s relatively easy to visualize blocks of “typists” or the same type of worker existing within the job-shop model (take one workers station on the line and duplicate it, looking at the example below we could duplicate B for instance multiple times leaving the connectivity the same). This model is one of the best for getting things done quickly, however it has problems of its own. Picture a three worker system:
Assume for the moment that each worker only has the option of passing jobs to the worker following their station. What would happen if worker C is the slowest? Workers A and B would have to go at the rate of C, which isn’t good for overall productivity. How about if worker B is the fastest overall? Worker B couldn’t go that fast because B can only operate at the rate that A can hand jobs to B and the rate at which C can accept them. This is a problem. Even if we measure each worker and align them to be perfectly rate matched, it’ll likely never actually occur again outside of the one time we measured it. Workers, as is the case with a thread/process/context running on a computer, are complex. What happens if B is really motivated after breakfast to go fast? B is still limited by A and C. How bout if A and B are really on the ball, but C just isn’t motivated for the moment? A and B could do a lot of work, if only they could pile up items for C to work on. From now on, this will be referred to as “bursty behavior.” It is temporary or transient (i.e., it only lasts for a short time…but could re-appear at any time, who knows what will motivate our workers to go faster). Worker behavior that causes jobs to pile up in-between workers consistently is caused by rate mismatch (e.g., if A is consistently faster than B, then A is limited by B). The terms “bursty” and “rate mismatch” will be used from now on as they are more technically appropriate.
So far we’ve assumed that each worker is simply handing jobs directly to the next worker. This is far from the case in many modern assembly lines (and indeed many of our programs). The most efficient way for many assembly lines is to buffer output between workers.

There are many reasons to buffer (using the A, B, C example above):
- Maybe worker B needs five of each job from A
- Accommodate bursty behavior of B when transitioning to C
But there are also some wrong reasons to buffer. What would happen if an assembly line attempted to correct rate mismatch with a warehouse in between worker stations (buffer). There are two scenarios (again, with A and B). If A goes significantly faster than B, it is fairly intuitive that B would fall behind. Items would pile up between A and B. What would happen over the course of a day? A year? Lets jump right to infinity. What would happen is an infinite number of jobs would pile up. This is bad, very bad. I don’t have infinite space, nor does anyone else. Using a queueing model, in this case a simple M/M/1 system (see Wikipedia page, formula for mean queue size is ) it is easy to show that as the arrival rate (rate at which A sends jobs to B equalizes, the number of jobs that piles up (shown on y-axis) between A and B piles up. In the image below I’ve plotted the number of items that would in fact pile up as the arrival rate is increased from almost zero to that almost equal to the rate at which B can service jobs (Note: I’ve not plotted the case where they are equal since infinity just blows the whole scale of the chart).
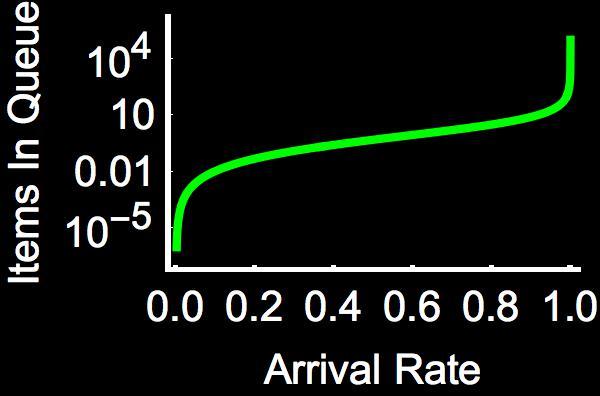
How about if B is far faster than A? A would find the buffer space between A and B almost always empty. There is a non-zero probability (that can be calculated) for bursty behavior to occur and for items to briefly pile up in the buffer. That probability can be calculated, and is sometimes useful, but for most purposes it’ll happen so infrequently that it won’t be a problem (this is a case of bursty behavior, just not the one most would jump to at first). The only word of caution I have is that infrequent events can happen at high enough rates or long enough running time.
One case not covered yet explicitly, because it can rarely happen in software processes, is where worker A directly hands items to worker B. This requires both workers to work (or service jobs if using queueing terminology) at the exact same rate in a deterministic manner. Before you can understand exactly why this works, the term deterministic must be understood to mean a system where no randomness is exhibited or involved in the determination of all future states. For an assembly line system this means that everything is done in lock-step, the exact same way, with the same rate, every time. This case usually only exists in the hardware world (and even then, physics often intervenes to add some unaccounted for behavior). For the purposes of software, a deterministic queue hardly ever exists (even perfectly engineered systems exhibit some variation, see this paper on best case execution variation link).
For software systems, these assembly line models suggest a few things:
- Fork-join parallelism is limiting, to get the most out of dividing a problem into tasks we need fork-join and pipeline parallelism (coincidentally both combined can be termed data-flow). This way all workers can execute as soon as data is ready for them to execute on. This is not the way most programs are written today.
- Load balancing is critical. Most current systems start by chunking, and then by work stealing to load-level each worker thread/process. But they tend to do it on a fork-join model vs. a pipeline model.
- It is not easy to get a balanced, and high performing parallel system.
Three are three general strategies for handling bursty behavior in parallel systems:
- Statically allocate huge, over-provisioned buffers between workers.
- Tie thread scheduling into the buffering system so that threads are scheduled only when there is room for their work to be communicated.
- Dynamically re-allocate buffers based on dynamic conditions.
Most systems take the first approach, a few take the second. Statically allocating giant buffers has several drawbacks. First and foremost, huge queues mean long latency and wait. Tying thread schedules to the size of buffers is a great approach, however it is complicated and often negates the possibility of enabling individual threads to go slightly faster given a custom sized buffer. Lastly, and even more complicated to implement in practice are dynamically resizing buffers. It is fairly easy to visualize a naive implementation of a dynamically resizing buffer, however building one that is high performance without locks is quite difficult. Getting rid of locks/atomic variables is critical, estimate around 45-50 cycles for a pthread_mutex, potentially more depending on the platform.
This post was mostly about workers, arrangements, and buffering. The next article (part 2) will be on the choice of parallelism modality and determining the amount of work to put in each thread. There are many modalities to choose from ranging from SIMD through heavy weight multi-node MPI. The choice of what to put in each context will also be covered, as each threading modality has a different (and non-zero) overhead of use.
Thanks for reading, as always feel free to leave comments, tweet, or share!
- RECOMMENDED CONFIGURATION VARIABLES: EDIT AND UNCOMMENT THE SECTION BELOW TO INSERT DYNAMIC VALUES FROM YOUR PLATFORM OR CMS.
- LEARN WHY DEFINING THESE VARIABLES IS IMPORTANT: https://disqus.com/admin/universalcode/#configuration-variables / / var disqus_config = function () { this.page.url = PAGE_URL; // Replace PAGE_URL with your page’s canonical URL variable this.page.identifier = PAGE_IDENTIFIER; // Replace PAGE_IDENTIFIER with your page’s unique identifier variable }; */ (function() { // DON’T EDIT BELOW THIS LINE var d = document, s = d.createElement(‘script’); s.src = ‘//managing-parallel-p1.disqus.com/embed.js’; s.setAttribute(‘data-timestamp’, +new Date()); (d.head || d.body).appendChild(s); })();